30 Sep 2021
If you are doing development or working with Kubernetes cluster api these are some helpful tips.
- clusterctl - helps with cluster creation but more importantly cluster debugging
- kubie - allows you to connect to multiple clusters at same as well as switch namespaces and clusters quickly. Helpful becuase it lets you be connected to both the management cluster and the workload cluster.
Getting a kind management cluster kubeconfig
kind get kubeconfig --name capz-e2e > kubeconfig.e2e
Getting a Workload Cluster kubeconfig
When connected to management cluster
kubectl get clusters
NAME PHASE
capz-conf-q6vvi1 Provisioned
Now download the clusters kubeconfig:
clusterctl get kubeconfig capz-conf-q6vvi1 > kubeconfig.e2e.conformance.windows
Viewing the state of the cluster
https://cluster-api.sigs.k8s.io/clusterctl/commands/describe-cluster.html
clusterctl describe cluster capz-conf-q6vvi1
NAME READY SEVERITY REASON SINCE MESSAGE
/capz-conf-q6vvi1 True 2m53s
├─ClusterInfrastructure - AzureCluster/capz-conf-q6vvi1 True 6m16s
├─ControlPlane - KubeadmControlPlane/capz-conf-q6vvi1-control-plane True 2m53s
│ └─Machine/capz-conf-q6vvi1-control-plane-845sj True 2m55s
└─Workers
├─MachineDeployment/capz-conf-q6vvi1-md-0
└─MachineDeployment/capz-conf-q6vvi1-md-win
└─2 Machines... False Info WaitingForBootstrapData 3m15s See capz-conf-q6vvi1-md-win-645fbb7c79-jhjjt, capz-conf-q6vvi1-md-win-645fbb7c79-vf44j
Using kubie
Use the kubeconfigs above to load a cluster:
kubie ctx -f kubeconfig.e2e
or if the cluster is in your default kubeconfig:
ssh’ing to capz machines
ssh’ing made easy in cluster api for azure (capz) VM’s and VMSS:
https://github.com/kubernetes-sigs/cluster-api-provider-azure/tree/main/hack/debugging#capz-ssh
Find the machine:
kubectl get azuremachine
NAME READY STATE
capz-cluster-0-control-plane-5b5fc true Succeeded
capz-cluster-0-md-0-fljwt true Succeeded
capz-cluster-0-md-0-wbx2r true Succeeded
Now ssh to it:
kubectl capz ssh -am capz-cluster-0-md-0-wbx2r
Deleting all of your dev clusters
Don’t do this in prod! :-)
kubectl delete cluster -A --all --wait=false
Add vim to Windows nodes
Sometimes you need to edit the files while developing:
iwr -useb get.scoop.sh | iex
scoop install vim
What else?
What are your favorites? What am I missing?
28 Apr 2021
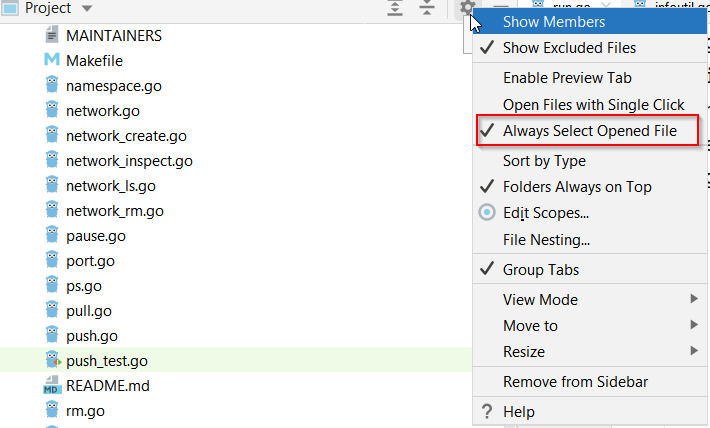
In a large code base it can be hard to figure out where files are. I’ve always enabled the “track active file in project drawer” in Visual Studio and VS Code. I’ve become a big fan Goland recently and found it hard to find this setting. So here it is:
01 Apr 2021
I have been working on making containerd work well on Windows with Kubernetes. I needed to do some local dev on containerd so I started to configure my local machine. I found lots of information here and there but nothing comprehensive so I wrote down my steps.
Note there are a few limitations with containerd (so you might not want to fully uninstall Docker). For instance, containerd doesn’t support building containers and you won’t be able to use the native Linux containers functionality (though there is some early support for LCOW).
Let’s get started!
Get Containerd
Get and install containerd:
curl.exe -LO https://github.com/containerd/containerd/releases/download/v1.4.4/containerd-1.4.4-windows-amd64.tar.gz
#install
tar xvf containerd-1.4.4-windows-amd64.tar.gz
mkdir -force "C:\Program Files\containerd"
mv ./bin/* "C:\Program Files\containerd"
"C:\Program Files\containerd\containerd.exe" config default | Out-File "C:\Program Files\containerd\config.toml" -Encoding ascii
Next for performance tell Windows defender to ignore it and start the service:
Add-MpPreference -ExclusionProcess "$Env:ProgramFiles\containerd\containerd.exe"
.\containerd.exe --register-service
Start-Service containerd
Setting up network
Unlike Docker, Containerd doesn’t attach the pods to a network directly. It uses a CNI (container networking interface) plugin to set up the networking. We will use the windows nat plugin for our local dev env. Not this is likely the plugin you would want to use in a kubernetes cluster, for that you should look at Calico, Antrea, or many of the cloud specific ones that are avalaible. For our dev environment NAT will work just fine.
Create the folder for cni binaries and configuration. The path C:\Program Files\containerd\cni\bin is the default location for containerd.
mkdir -force "C:\Program Files\containerd\cni\bin"
mkdir -force "C:\Program Files\containerd\cni\conf"
Get the nat binaries:
curl.exe -LO https://github.com/microsoft/windows-container-networking/releases/download/v0.2.0/windows-container-networking-cni-amd64-v0.2.0.zip
Expand-Archive windows-container-networking-cni-amd64-v0.2.0.zip -DestinationPath "C:\Program Files\containerd\cni\bin" -Force
Create a nat network. For nat network it must have the name nat
curl.exe -LO https://raw.githubusercontent.com/microsoft/SDN/master/Kubernetes/windows/hns.psm1
ipmo ./hns.psm1
$subnet="10.0.0.0/16"
$gateway="10.0.0.1"
New-HNSNetwork -Type Nat -AddressPrefix $subnet -Gateway $gateway -Name "nat"
Set up the containerd network config using the same gateway and subnet.
@"
{
"cniVersion": "0.2.0",
"name": "nat",
"type": "nat",
"master": "Ethernet",
"ipam": {
"subnet": "$subnet",
"routes": [
{
"gateway": "$gateway"
}
]
},
"capabilities": {
"portMappings": true,
"dns": true
}
}
"@ | Set-Content "C:\Program Files\containerd\cni\conf\0-containerd-nat.conf" -Force
Creating containers
There are two main ways to interact with containerd: ctr and crictl. ctr is great for simple testing and crictl is used to interact with containerd in the same way that kubernetes works.
CTR
Ctr was already installed when you pulled the binaries and installed containerd. It has a similiar interface to docker but it does vary some since you are working at a different level.
There is a bug with ctr that doesn’t support multi-arch images on Windows (PR to fix it) so we will use the specific image that matches our operating system. I am running Windows 10 20H2 (build number 19042) so will use that tag for the image.
# find your version
cmd /c ver
Microsoft Windows [Version 10.0.19042.867]
cd "C:\Program Files\containerd\"
./ctr.exe pull mcr.microsoft.com/windows/nanoserver:20H2
./ctr.exe run -rm mcr.microsoft.com/windows/nanoserver:20H2 test cmd /c echo hello
hello
Create a pod via crictl
Using CRI api can be alittle cumbersome. It requires doing each step independently.
Get the crictl and install it to a directly:
curl.exe -LO https://github.com/kubernetes-sigs/cri-tools/releases/download/v1.20.0/crictl-v1.20.0-windows-amd64.tar.gz
tar xvf crictl-v1.20.0-windows-amd64.tar.gz
Set up defaults for crictl that will connect to containerd’s default named pipe so it doesn’t need to be set for each call with crictl.
@"
runtime-endpoint: npipe://./pipe/containerd-containerd
image-endpoint: npipe://./pipe/containerd-containerd
timeout: 10
#debug: true
"@ | Set-Content "crictl.yaml" -Force
Pull an image
./crictl pull k8s.gcr.io/pause:3.4.1
Create the sandbox, container and run it (told you its a bit cumbersome).
$POD_ID=(./crictl runp .\pod.json)
$CONTAINER_ID=(./crictl create $POD_ID .\container.json .\pod.json)
./crictl start $CONTAINER_ID
Finally exec in and check the pod has an IP address from the network we crated earlier.
First lets take a look at the network and endpoint that was created for the pod:
get-hnsnetwork | ? Name -Like "nat" | select name, id, subnets
Name ID Subnets
---- -- -------
nat D95007EB-27C6-4EED-87FC-402187447637 {@{AdditionalParams=; AddressPrefix=10.0.0.0/16; Flags=0; GatewayAddress=1...
Get-HnsEndpoint | ? virtualnetworkname -like nat | select name, id, ipaddress, gatewayaddress
Name ID IPAddress GatewayAddress
---- -- --------- --------------
92c0776a2fa06e2ce0a074b350146ed9e97bb2dafdb5bf0b8f8c55c8d4020f00_nat 50f2bd95-90c2-4234-8d82-ef45c841dfb4 10.0.113.113 10.0.0.1
Now exec into the container and look at the network config
./crictl exec -i -t $CONTAINER_ID cmd
C:\>ipconfig
Windows IP Configuration
Ethernet adapter vEthernet (92c0776a2fa06e2ce0a074b350146ed9e97bb2dafdb5bf0b8f8c55c8d4020f00_nat):
Connection-specific DNS Suffix . : home
Link-local IPv6 Address . . . . . : fe80::3034:e49c:68b4:99ac%88
IPv4 Address. . . . . . . . . . . : 10.0.113.113
Subnet Mask . . . . . . . . . . . : 255.255.0.0
Default Gateway . . . . . . . . . : 10.0.0.1
You will note the endpoint is the name as the Ethernet Adapter and the ipddresss and default gateway match.
Helpful links that I used to compile this walk through
06 Jun 2020
I have been working on adding IPV6 support to the Azure cluster api provider (CAPZ) over the last few weeks. I ran into some trouble configuring Calico as the Container Networking Interface (CNI) for the solution. There are some very old (2017) and popular (updated 13 days ago at time of writing) issues on github where folks are looking for ways to fix the issue.
This is obviously something that is hard to debug due to the error message being vague and the wide variety of CNI’s available and the wide range of issues that could be causing it. The original issues did seem to be root caused but others (me included) are still running into the issue regularly. In my case, I was already running the latest version of my cni (plus just running the latest isn’t really understanding the root cause) and I understand why removing environment variables doesn’t really help. I figured I had simply configured something wrong but what was it?
Debugging CNI issues with Kubelet
The dreaded error message from Kubelet is:
kubelet: E0714 12:45:30.541001 7263 kubelet.go:2136] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message: network plugin is not ready: cni config uninitialized
Unfortunately this is not very descriptive. Sometimes kubelet has other error messages in it that give you pointers to what is wrong but in my case there was nothing in the logs. The CNI itself wasn’t working but there weren’t any error logs that I could find.
After a big of digging I found the a developer tool for executing CNI’s manually. This allows you to attach an interface to an already created network namespace via a CNI you provide. After building the tool, it is pretty straight forward to execute it with the cni and configuration that is installed on the kubernetes node.
It assumes the cni config is installed to /etc/cni/net.d and /opt/cni/bin where cni’s are typically installed if you use kubeadm:
# create a test network namespace
sudo ip netns add testingns
# run with default config location
sudo CNI_PATH=/opt/cni/bin cnitool add uniquename /var/run/netns/testingns
Discovering the bug
In my case it was a simple misconfiguration, can you spot it?
Important: be careful with the Calico spec below. It is likely not what you are expecting. At the time of writing Calico vxlan doesn’t support IPV6 which is one of the ways to run Calico on Azure. Another way is to use UDR’s and host-local ipam which requires --configure-cloud-routes in the cloud provider which is what is happening above. I also has the misconfiguration in it.
---
# Source: calico/templates/calico-config.yaml
# This ConfigMap is used to configure a self-hosted Calico installation.
kind: ConfigMap
apiVersion: v1
metadata:
name: calico-config
namespace: kube-system
data:
# Typha is disabled.
typha_service_name: "none"
# Configure the backend to use.
calico_backend: "none"
# The CNI network configuration to install on each node. The special
# values in this config will be automatically populated.
# https://docs.projectcalico.org/reference/cni-plugin/configuration#using-host-local-ipam
cni_network_config: |-
{
"name": "k8s-pod-network",
"cniVersion": "0.3.1",
"plugins": [
{
"type": "calico",
"log_level": "info",
"datastore_type": "kubernetes",
"nodename": "__KUBERNETES_NODE_NAME__",
"mtu": 1500,
"ipam": {
"type": "host-local",
"subnet": "usePodCidr",
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "__KUBECONFIG_FILEPATH__"
}
},
{
"type": "portmap",
"snat": true,
"capabilities": {"portMappings": true}
}
]
}
Yes, that is comma after "usePodCidr" which gave the cryptic error message network plugin is not ready: cni config uninitialized. Fun times with json embedded in yaml :-) After removing it everything behaved as expected.
Next steps
I am going to take a look at the K8s/cni code to figure out if it’s possible to bubble up better error message as this is obviously a pain point for folks.
16 Oct 2018
When deploying an Azure Kubernetes Service cluster you are required to use a service principal. This service principal is used by the Kubernetes Azure Cloud Provider to do many different of activities in Azure such as provision IP addresses, create storage disks and more. If do not specify a Service principal at the time of creation for the an AKS cluster a service principal is created behind the scenes.
In many scenarios, the resources your cluster will need to interact with will be outside the auto-generated node resource group that AKS creates. For instance, if you are using Static IP address for some of you services, the IP addresses might live in a resource group outside the auto-generated node resource group. Another common example is attaching to an existing vnet that is already provisioned.
Assigning proper permissions
It would be simple to give Contributor rights across your whole sub or even individual resource groups and these scenarios would work but this is not a good practice. Instead we should assign the specific, least privileged rights to a given service principal.
In the examples of attaching IP addresses, we may need the Azure Cloud Provider to be able to attach but not delete IP addresses because a different team controls the IP address. We definitely don’t want the Service principal to be able to delete any other resources in the resource group.
There is a good list of the Kubernetes v1.11 permissions required here. This list shows the permissions for creating a least privileged service principal (note that it might change as k8s version change so use as general guide). Using this we can assign just enough rights to the service principal to interact with the resources outside the node group.
Sample Walk through
I have created a full walk through sample of creating the service principal upfront and assign just enough rights to it to access the IP addresses and vnet. Here is a highlight of the important parts:
First create a service principal with no permission:
clientsecret=$(az ad sp create-for-rbac --skip-assignment -n $spname -o json | jq -r .password)
Using custom Role Definitions I am able to give the service principal only read access to the IP’s:
{
"Name": "AKS IP Role",
"IsCustom": true,
"Description": "Needed for attach of ip address to load balancer created in K8s cluster.",
"Actions": [
"Microsoft.Network/publicIPAddresses/join/action",
"Microsoft.Network/publicIPAddresses/read"
],
"NotActions": [],
"DataActions": [],
"NotDataActions": [],
"AssignableScopes": [
"/subscriptions/yoursub"
]
}
Using that definition we can then apply the Role Definition to the Service principal which will give it IP read access to the resource group:
spid=$(az ad sp show --id "http://$spname" -o json | jq -r .objectId)
iprole=$(az role definition create --role-definition ./role-definitions/aks-reader.json)
az role assignment create --role "AKS IP Role" --resource-group ip-resouce-group --assignee-object-id $spid
Then you can deploy your cluster using the service principal:
az aks create \
--resource-group aks-rg \
--name aks-cluster \
--service-principal $spid \
--client-secret $clientsecret
This will allow the Service principal used to access the the IP Addresses in the resource group outside the node.
note: to access the ip address in group outside the cluster you will need to provide an annotation on the k8s Service definition (service.beta.kubernetes.io/azure-load-balancer-resource-group). See the example.
Check out the sample for a full walk through.